Anti-pattern: advanced messaging systems
The "advanced" messaging system industry with products like RabbitMQ, NServiceBus, ActiveMQ and Artemeis embody several anti-patterns:
- persistent messages which involves the unnecessary persistence anti-pattern.
It's also called Database as IPC [
 ]
] - out-of-order messaging
- unreliable messaging
- pub-sub messaging systems
- at least once delivery
- de-duplication
- smart middleware/routers/brokers (instead of
directory services [])
- a "smart network", at odds with principles on which the Internet was designed, such as
the end-to-end principle [] - that
application-specific features reside in the communicating end nodes of the network,
rather than in intermediary nodes. For example TCP sits on top of IP and embodies the
end-to-end principle
It's no accident that the common protocols on the Internet weren't built on these anti-patterns.
The anti-patterns embodied in advanced messaging systems have a domino effect, in the complexity and inefficiency of the whole system. See a talk by Udi Dahan where he proposes a complex solution to a non-problem.
Data replication versus application level messaging
Application level messaging is typically unnecessary when data replication is available. This point is discussed in the context of the book Enterprise Integration Patterns by Gregor Hohpe and Bobby Woolf.
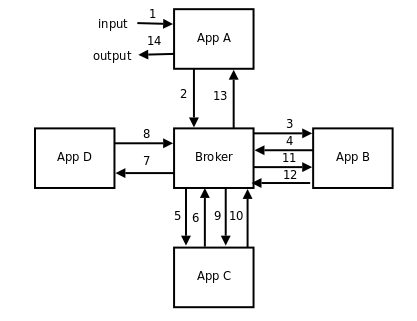
Broker versus brokerless
The 0MQ whitepaper brokerless points out a broker requires an excessive amount of network communication. An example is given of 12 hops with a broker and 3 hops without a broker:

Apache Kafka
Apache Kafka is a distributed streaming platform where consumers uses a sequence number to record what records they have consumed so far.
Unfortunately Kafka embodies a fundamental anti-pattern. For example, rather than make it easy to solve the problem of correctly transferring money/stock between participating databases, it makes the problem harder to solve correctly.
WS-ReliableMessaging
The protocol WS-ReliableMessaging allows SOAP messages to be reliably delivered between distributed applications in the presence of software component, system, or network failures. It supports exactly once, in order messaging.
According to the 62 page specification:
The protocol enables the implementation of a broad range of reliability features which include ordered Delivery, duplicate elimination, and guaranteed receipt. The protocol can also be implemented with a range of robustness characteristics ranging from in-memory persistence that is scoped to a single process lifetime, to replicated durable storage that is recoverable in all but the most extreme circumstances. It is expected that the Endpoints will implement as many or as few of these reliability characteristics as necessary for the correct operation of the application using the protocol. Regardless of which of the reliability features is enabled, the wire protocol does not change
The complexity is apparent in the paper Web Services Reliability Patterns which shows a class diagram for the WS-Reliable Messaging pattern:

Nobody Needs Reliable Messaging
In the article Nobody Needs Reliable Messaging Marc de Graauw discusses the usefulness of the WS-ReliableMessaging protocol

He concludes WS-ReliableMessaging is solving a non-problem:
With a bit further tightening of the business logic, which requires unique prescriptions anyway, we can have a much simpler solution.
If reliability is important on the business level, do it on the business level. A Reliable Messaging layer can handle only generic logic, but that's not what we want: we want business-specific logic for in-order and exactly-once processing.
Exactly once delivery is possible
In the blog post You Cannot Have Exactly-Once Delivery by Tyler Treat (2015), it is stated:
Within the context of a distributed system, you cannot have exactly-once message delivery.
This is incorrect, for example TCP provides exactly one in order delivery semantics for applications, by using positive acknowledgement with re-transmission for at least once delivery, and sequence numbers and a sliding window for de-duplication and ordering. This is all done in the transport layer, providing exactly once semantics for applications.
In fact the author contradicts himself when he writes:
The way we achieve exactly-once delivery in practice is by ...
and
This can be used to simulate exactly-once semantics by ...
The word "simulate" appears to be suggesting the exactly-once semantics isn't real, but of course it is.
The problem is not that exactly-once semantics is impossible, rather that it's unnecessarily inefficient and cumbersome to achieve when using messaging systems like RabbitMQ.
AMQP
AMQP (Advanced Message Queuing Protocol) is an open standard for passing business messages between applications or organizations. The AMQP Version 1.0 specification is 125 pages. It's ridiculously complicated and yet it's needless complexity.
The original developer of AMQP was iMatix. The iMatix CEO Pieter Hintjens wrote about the problems with AMQP in 2008, and in 2010 announced that iMatix would leave the AMQP workgroup and did not plan to support AMQP/1.0 in favor of the significantly simpler and faster ZeroMQ.
Message throughput
Most advanced message queue products provide little information about performance - even though it's very easy to write microbenchmarks. Microbenchmarks are useful because they provide upper bounds on the performance that can be achieved in a real system.
Often the message bus products exhibit very poor performance - far less than what could be achieved by simply sending messages directly over a TCP/IP connection.
MSMQ Transactional queues have very poor performance - e.g. only 40 messages per second reported here: What am I missing? MSMQ Perf Issue by Ayende Rahien (2009).
NServiceBus has been reported as giving poor performance, probably because it sits on top of MSMQ transactional queues. See for example NServiceBus out-of-the box gives very poor performance, or the stackoverflow query Poor performance of NServiceBus over MSMQ.
Udi Dahan discussed the performance of NServiceBus in his blog post NServiceBus Performance (2008). He says "we were pumping around 1000 durable, transactionally processed messages per second, per server". However there is no information about the number of cores, network, number of queues, sizes of the messages etc.