Kafka
Apache Kafka is a distributed streaming platform, that runs as a cluster on one or more servers.
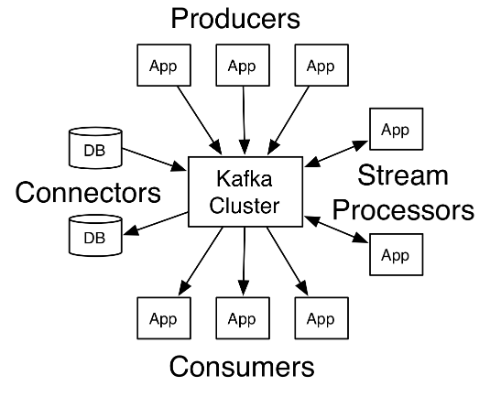
The Kafka cluster durably persists all published records — whether or not they have been consumed using a configurable retention period.
That's essentially a broker which persists messages which is an anti-pattern.
Consumers use a sequence number to record what records they have consumed so far:
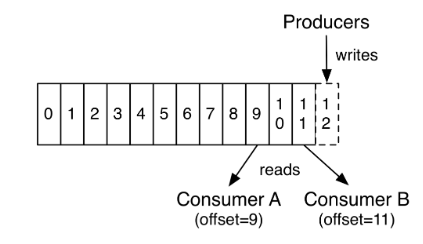 That's great, it's an important part of how to do messaging the right way.
That's great, it's an important part of how to do messaging the right way.
Unfortunately, there's a fundamental problem: The persistent queue pattern requires the persistent queue to be in the producer database, not inside a separate database in a broker.
This ruins the ability to atomically remove money or stock from accounts on the producer and send deposit records to consumers. Rather than help implement solutions that correctly transfer money/stock between participating databases, it only makes the problem harder to solve correctly.
From CRUD to Event Sourcing
In James Roper's blog post From CRUD to Event Sourcing (2018) he claims event sourcing ultimately yields a simpler, more resilient and easier to maintain system when implementing microservices. He says:
To be honest, event sourcing does generally require writing more code up front than CRUD. Lagom does not push event sourcing because it reduces the amount of code. Lagom pushes event sourcing because the problems that microservices introduce - such as ensuring consistency between services - are very easily solved when you are using event sourcing for persistence, and very hard to solve when you’re using CRUD for persistence. A service using CRUD might have less code to start with, but as soon as it starts sharing data with other services, problems relating to handling failures and synchronisation of state become very difficult problems to solve, and will often require implementing complex solutions, including manual state and failure tracking.
In his video about the topic, he explains his reasoning. It arises because he uses a broker which persist messages (in his example it's Kafka). There is a problem with not being able to atomically update the CRUD database and publish a message to Kafka.
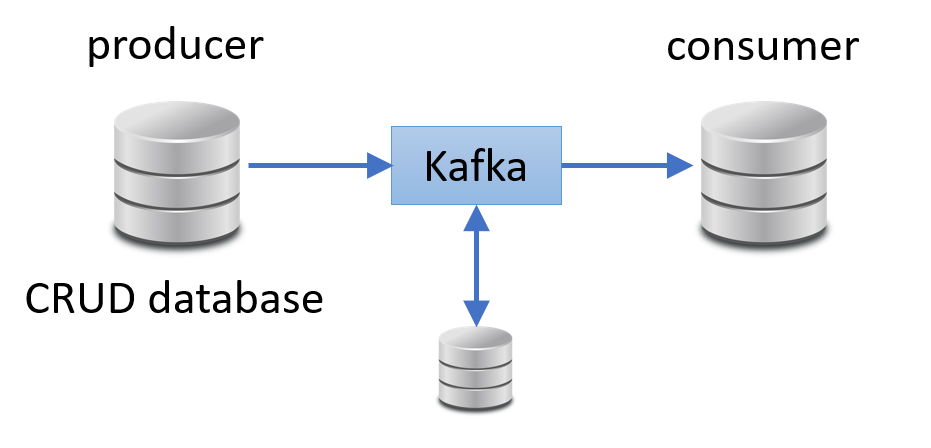
His solution is to replace the CRUD database at the producer with an events database, and persist a producer sequence number to allow the producer to implement at least once delivery of the relevant events as messages sent to Kafka. Kafka is able to use the sequence number to detect and drop the duplicates, and the consumer persists a sequence number in its own database to similarly ensure it processes the messages it receives from Kafka exactly once.
This begs the question, why use Kafka at all? The producer already offers message persistence and the ability to send messages from a given sequence number. The consumer already persists a sequence number in its database recording how many messages it has consumed. That's made Kafka redundant. In fact much worse than redundant. Why not simply stream the messages exactly once directly from producer to consumer using TCP?
This is far superior to having the producer update a persistent sequence number according to what has been acknowledged as durable by Kafka. In the section Availability and Durability Guarantees of the official Kafka documentation, it is stated:
When writing to Kafka, producers can choose whether they wait for the message to be acknowledged by 0,1 or all (-1) replicas.
It appears that the only way to determine whether a message sent to Kafka has been made durable is to wait for an acknowledge - that's a network round trip.
Push versus pull
In the documentation on push vs. pull it is stated:An initial question we considered is whether consumers should pull data from brokers or brokers should push data to the consumer. In this respect Kafka follows a more traditional design, shared by most messaging systems, where data is pushed to the broker from the producer and pulled from the broker by the consumer. Some logging-centric systems, such as Scribe and Apache Flume, follow a very different push-based path where data is pushed downstream. There are pros and cons to both approaches. However, a push-based system has difficulty dealing with diverse consumers as the broker controls the rate at which data is transferred. The goal is generally for the consumer to be able to consume at the maximum possible rate; unfortunately, in a push system this means the consumer tends to be overwhelmed when its rate of consumption falls below the rate of production (a denial of service attack, in essence). A pull-based system has the nicer property that the consumer simply falls behind and catches up when it can.
It is unclear what is thought to be the problem with a push model. If TCP is used, then TCP flow control will kick in when the consumer rate of consumption falls below the rate of production. It never "overwhelms" the consumer.
The TCP ACKs achieve flow control and it's automatic and uses
piggybacking [![]() ] to improve efficiency and
available channel bandwidth.
] to improve efficiency and
available channel bandwidth.
It is claimed a pull-based system has the "nicer property that the consumer simply falls behind and catches up when it can". This is a strange claim given that a push-based system using TCP is no different.
The push model is superior because it is avoids the latency involved with requesting message before they are sent, and it allows better utilisation of the available channel bandwidth.
Multiplexing and flow-control
The only potential advantage of a pull model occurs when a channel is multiplexed [![]() ].
That is, where one shared channel is used for multiple subchannels.
].
That is, where one shared channel is used for multiple subchannels.
The issue is that a slow consumer on one subchannel might interfere with the throughput on another subchannel, if flow control is only implemented on the shared channel.
The solution with a push model is to implement flow control on the subchannels. This is an elegant approach because flow control is an implementation detail of the multiplexing system (rather than being complexity forced onto application programmers - such as the idea of AMQP link credits - see section 2.6.7 of the OASIS Advanced Message Queuing Protocol (AMQP) Version 1.0).
Alternatively, just avoid multiplexing in the first place.
Exactly once messaging
Consider the article Exactly once Semantics are Possible: Here’s How Kafka Does it by Neha Narkhede (2017) which claims exactly once delivery is a really hard problem:
Now, I know what some of you are thinking. Exactly once delivery is impossible, it comes at too high a price to put it to practical use, or that I’m getting all this entirely wrong! You’re not alone in thinking that. Some of my industry colleagues recognize that exactly once delivery is one of the hardest problems to solve in distributed systems.
Now, I don’t deny that introducing exactly once delivery semantics — and supporting exactly once stream processing — is a truly hard problem to solve. But I’ve also witnessed smart distributed systems engineers at Confluent work diligently with the open source community for over a year to solve this problem in Apache Kafka.
These are complex solutions caused by using anti-patterns in the first place. The complexity is apparent in the confluence article Transactional Messaging in Kafka. See also the blog Transactions in Apache Kafka by Apurva Mehta and Jason Gustafson 2017. Also there is a 67 page google document for the design: Exactly Once Delivery and Transactional Messaging in Kafka.
Jay Kreps wrote an article Exactly-once Support in Apache Kafka in 2017 defending the claim that exactly once is possible. The author says the problem is equivalent to consensus and says consensus is the mainstay of modern distributed systems development (despite the FLP theorem which proves that consensus is impossible in a fully asynchronous system). The author is correct that there are practical solutions to consensus problems, but they cannot be fully asynchronous and they're complicated (e.g. Paxos and Raft).
When a persistent message broker is avoided in the first place, and one simply uses a persistent queue then there is no need to solve a consensus problem. Exactly once delivery is not a "truly hard problem", it's trivial when Kafka isn't used at all. This is the sense in which messaging systems like Kafka make things vastly more complicated and less efficient than they need to be.
Kafka Exactly Once Semantics by Vivek Sinha refers to Kafka’s Exactly once semantics as a holy grail, and says "before, people believed that it is not mathematically possible in distributed systems. This announcement raised eyebrows in the community". See also Adam Warski's article What does Kafka's exactly-once processing really mean? in 2017 and Himani Arora's article Exactly-Once Semantics With Apache Kafka in 2018.