Events databases
It has been common for database systems to manage records with the four
CRUD [![]() ]
functions (Create, Read, Update, Delete).
The Update and Delete functions imply that the state is mutable.
The database is regarded as representing the current state of affairs which
is updated over time.
]
functions (Create, Read, Update, Delete).
The Update and Delete functions imply that the state is mutable.
The database is regarded as representing the current state of affairs which
is updated over time.
Perhaps this is because most programmers think in terms of mutable state. For example OO programmers have a tendency to think in terms of objects which are state machines that mutate. This is quite different to thinking of information systems as simply accreting facts that have happened. The etymology of the word “fact” comes from the Latin factum which is the past participle of facere (‘do’). It literally means something done.
Independently of the computer industry, mature businesses emphasise the append-only recording of immutable events that occur at moments in time, rather than mutable state representing the current state of affairs which is repeatedly updated. For example double entry bookkeeping began about a thousand years ago, and one of the reasons for its success is that it provides an audit trail. As another example, contracts written by lawyers use addendums to change the terms.
A distinction can be made between predicates about the world that record events that have happened, such as:
Employee [Id] began employment on [Date]
versus predicates about the current state of things, such as:
There is currently an employee [Id] in department [DeptId]
When the predicates record events that have happened there is a very direct and simple relationship between the database operations and real world processes - just record the new events that have happened.
By contrast when the predicates are about the current state of things there is a tendency for a more complex schema, more complex updates and more complex constraints. There's a tendency to produce designs that aren't normalised. There's a tendency for small changes in the real world to require large changes in the database. This not only increases the load on writers, it also upsets opportunities for concurrency.
The main justification for using predicates about the current state of things is performance. It is assumed that it is too expensive to derive the current state from the events. However that is unlikely, it is very easy and very efficient to calculate derived state asynchronously from events using a pipeline architecture. This is by far the best way to achieve high performance.
Quite often one sees an approach to temporal data involving predicates using time intervals instead of timestamps. For example, see Time and Relational Theory: Temporal Databases in the Relational Model and SQL by C.J. Date, Hugh Darwen and Nikos Lorentzos. An example of a predicate involving a time interval is:
Supplier [S] was under contract during the time interval [I]
A downside of using time intervals is that it complicates the semantics for defining the predicates in an unambiguous way - i.e. so that the time intervals are maximal in some sense. An advantage relates to notions of packing/unpacking predicates on a time attribute.
Let an events database mean a database where the base representation (which is the target of updates) involves predicates that record events that have happened.
There are significant advantages to an events database such as:
- Higher ingestion rate (append is more efficient than insert/update)
- Atomicity easier to achieve (less writing in-place)
- Snapshot isolation is simpler and more efficient (most data is immutable, and therefore independent of what snapshot of the database is being read)
- Eliminates the need for Optimistic Concurrency Control when updating records – because records are not updated in the first place
- Cached records (e.g. in products like Hibernate) never become stale
- Asynchronous reads - records don't become stale by the time you get them
- It’s actually reasonable to use third party caching products (like MemCached)
- Better orthogonality in the schema (space-time events tend to be independent – so writers don’t interfere with each other)
- An events database implicitly records all history, all possible versions
- Events represent very space efficient deltas between versions of the current state of the world
- Events are well suited to high performance pipeline/stream/message based architectures. Event producers create a stream of events as they happen, and the events can be streamed Exactly Once In Order (EOIO) to consumers to process them, using left folds
In the OO community the approach is sometimes called Event Sourcing. But the idea is hardly new. Recording information using events of course predates the computer industry. If anything the computer industry have inappropriately emphasised mutability in information systems, even though information systems should usually be regarded as accreting events as they happen.
The “current state” can be regarded as a left fold [![]() ] over the events.
Since the events are immutable, it is straightforward to calculate left folds over the
events asynchronously.
The ability to quickly retrieve the state of the world at different moments in
time can require appropriate caching of partial left folds
(which is analogous to a sequence of partial sums [
] over the events.
Since the events are immutable, it is straightforward to calculate left folds over the
events asynchronously.
The ability to quickly retrieve the state of the world at different moments in
time can require appropriate caching of partial left folds
(which is analogous to a sequence of partial sums [![]() ]).
]).
Events represent versioned sets very efficiently. There are timestamped events for insertions and deletions on a set, allowing the set to be derived at any moment in time. For example, in a genealogy database, the set of people alive at a given moment in time equals the set of people that have been born before that time minus the set of people that have died before that time.
Generally speaking records should be recorded in the database in time order, so that new events only need to be appended, and it also allows for fast range queries on time, and for iteration over records in time order for the purpose of calculating left folds.
An events database fits in well with the notion to distinguish between a relatively unconstrained base representation for writers, and a more constrained representation for readers. See constraints.
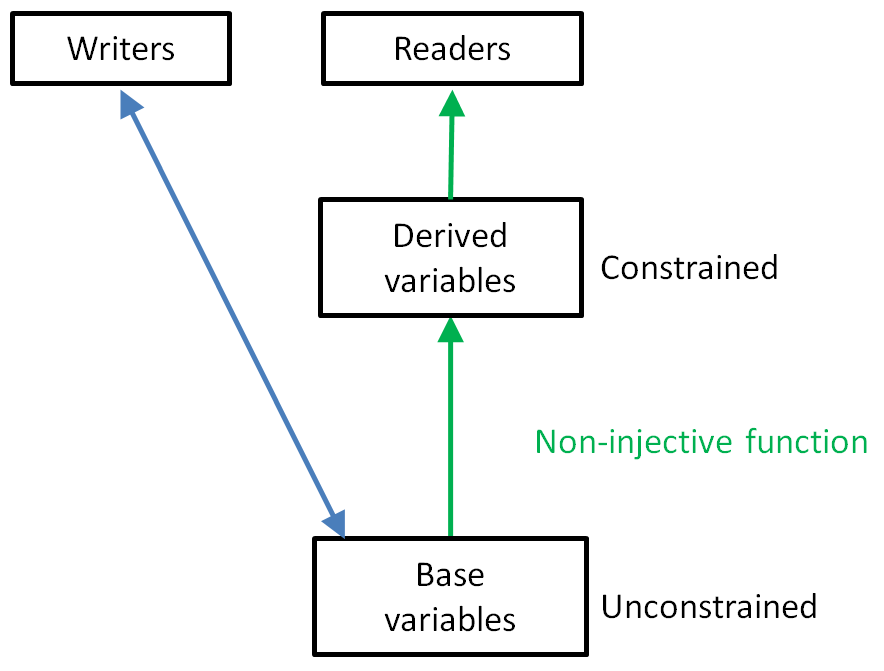
One of the great things about this approach is that it is optimal for writers, and allows for readers to be fully asynchronous and to use a different schema, so we can optimise for readers as well.
An emphasis on immutable data makes it easier to merge concurrent edits - so Operational Transformation is more efficient.
In a fully asynchronous distributed system (so there are no synchronised clocks), there is a natural generalisation of time called a vector time, and the states of the system that preserve causality form a lattice.
Vector times play an important role in event streaming in a fully asynchronous distributed system (see multiple producers and consumers which represents simple, efficient, reliable, exactly once "publish-subscribe" with multiple publishers and multiple subscribers)