Notes
This is for ideas in the pipeline...
Consistency
CEDA guarantees
1) Each site has sequential consistency.
2) An order constraint is imposed on writes - they must preserve causality. This is achieved
using vector timestamps.
Causal consistency [![]() ]
Potentially causally related writes must be observed in the same order by all processes.
For different machines, concurrent writes may be observed in different orders.
See Causal Consistent Databases
by Mawahib Musa Elbushra A, Jan Lindstrom, 2015.
Causal consistency is stronger than eventual consistency.
CEDA is strong evential consistency:
SEC: Whereas eventual consistency is only a liveness guarantee (updates will be observed eventually),
strong eventual consistency (SEC) adds the safety guarantee that any two nodes that have received the
same (unordered) set of updates will be in the same state.
CEDA is monotonic : the application will never suffer rollbacks.
]
Potentially causally related writes must be observed in the same order by all processes.
For different machines, concurrent writes may be observed in different orders.
See Causal Consistent Databases
by Mawahib Musa Elbushra A, Jan Lindstrom, 2015.
Causal consistency is stronger than eventual consistency.
CEDA is strong evential consistency:
SEC: Whereas eventual consistency is only a liveness guarantee (updates will be observed eventually),
strong eventual consistency (SEC) adds the safety guarantee that any two nodes that have received the
same (unordered) set of updates will be in the same state.
CEDA is monotonic : the application will never suffer rollbacks.
Conflict-free replicated data type
See: Conflict free replicated data type [![]() ]
]
Benefits of weak constraints
We want lots of vertical slices. That's upset by constraints on the data. We need prime factorisation where the factors are inside vertical slices. That means they can be updated independently.
A lot of people wonder how they will deal with eventual consistency. It sounds so dangerous. Consistency issues is dominated by integrity constraints. Relaxing constraints makes evential consistency work so much better.
What does consistency actually mean? In our solution for transferring money between accounts, it is always consistent, depending on how you look at it - if we account for the money recorded in the queues which are like accounts representing money being transferred.
Benefits of OT
OT allows for sandboxing. Sandboxing allows a user to control when they publish.
The best way to achieve availability is to replicate data. Without the replication, a distributed system is less robust, not more. All things being equal, more moving parts means more things can go wrong.
Don't bake deployment decisions into most code
Good software design/implementation approaches don't lock in physical deployment decisions. That even includes microservice versus monolithic. Most of the code should be the same!
OO versus RM
Eric Evans says a word like "customer" means something specific in a bounded context. A lot of that is to allow it to be modelled reasonably with OO.
class Customer
{
String name;
Address address;
PhoneNumber homePhoneNumber;
PhoneNumber mobilePhoneNumber;
...
};
But in the RM we have less of a problem because we don't even try to come up with a model of a "customer". Instead we just have any number of predicates about customers. We can add more as we like. There's hardly confusion over what's meant by an indentifier of a human. We don't need to appeal to some carefully defined bounded context to agree on the concept of identifying a human.
Event streaming
The current state is a left fold over the events.
To fix errors in the events themselves we cannot update the events because they are immutable and the events database is append only. The solution is to create events when represent corrections. The easiest way is to have a "cancel" event, instead of trying to correct part of an event. This is easier and also allows for understanding intentions - which is often why we want an events database in the first place.
There are two ways to avoid very long event streams, which are expensive to calculate left folds over: One is to map a key to an event stream, so there are lots of smaller event streams. For example, all the events on one bank account. Another is to left fold from a base line. E.g. this might be done every 3 months. This allows for purging data.
Examples of event sourcing already done: - accounting - lawyer contracts (with addendums) - genealogy
A bank account balance is a left fold over the transaction events. If we want to ensure the balance never goes negative then the writer needs synchronous access to the account balance. So we don't calculate it asychronously. That's fine, it makes sense for some left folds to be available to the writers, when it's important to allow the data to be edited in a menaingful way. Consider a CAD drawing.
CEDA allows for many of the advantages of event sourcing when event sourcing isn't used.
CEDA is well suited for providing general support for streaming the operations over data, for allowing other read databases to perform left folds over the operations. In particular this is how CEDA would sync with a relational database.
Using a grammar to define a binary format
Grammars tend to be regarded as being used to define human editable text languages. However, they are also great for binary languages. Indeed binary languages tend to be simpler than text languages. For example, rather than use commas between items in a list, we simply have juxtaposition. Of course binary languages are much more efficient on both space and computing resources.
Review of EIP book
On page 38 of the introduction it is stated: Asynchronous communication has a number of implications. ... However concurrent threads also make debugging more difficult. ... However this means that the caller has to be able to process the result even while it is in the middle of other tasks, and it has to be able to remember the context in which the call was made. ... But it also means that the sub-processes must be able to run independently in any order, and the caller must be able to determine which result came from which subprocess and combine the results together. These are big disadvantages of asynchronous messaging that go away in CEDA. On page 12-14 of chapter 1 a "minimalist integration solution" using TCP/IP is used and it is claimed it is brittle because the parties make assumptions about the representation of numbers and objects, they use hard-coded machine addresses, they have to be available at the same time, and the list of parameters and their types must match. On page 14 they say "In order to make the solution more loosely coupled, we can try to remove these dependencies one by one. We should use a standard data format that is self describing and platform independent, such as XML" This is just plain wrong: - You can't send data between parties without making assumptions, it's unavoidable. - With asynchronous models, the assumption that they aren't connected all the time is taken care of. A broker should be avoided wherever possible. - There ARE standards for binary serialisation of data types (e.g. little endian signed 32 bit number, or IEEE 767 formats for floats) and they ARE platform independent. - Self describing formats is taken care of with support for serialiable variant types. This is a confusion that seems to permeate the industry. You can't send data between parties without making assumptions. If you use XML then you're making at last as many assumptions as when you use a more efficient binary format. The claim that binary formats don't have standards is incorrect. On page 16 they speak of translation of *messages* between systems. This is wrong headed. Instead it is better to - Use cross-language modules which lets you define types and serialise/deserialise them. This lets you send/receive values of those types. These modules encapsulate the assumptions about representation. - Use translation between values of types (either on send side or receive side)When software is done right
When software is done right, it feels right to the programmers. It's elegant, simple, maintainable, solves a useful problem. That's more important than a 100 tests that succeed.
The importance of a deep knowledge of the domain
The most important and useful programmer is one that is not only writing the code but also has a deep knowledge of the domain.
Don't merely ask the users what they want. Find out what they need. Make sure the development is driven by the most important requirements. Fewer features can be better than more. Users tend to want simple/robust/performant software. Features often make the user experience worse. Make sure the product owner is getting this right and determining the value of the tasks appropriately. The product owner sets the tasks to be done and their priority, not a manager. It should be remembered that the product is the user interface. So the user interface should drive the architecture.
Test pyramid
It's quite common to see a test pyramid discussed. For example the article The Agile Testing Pyramid by Roger Brown shows the following figure:
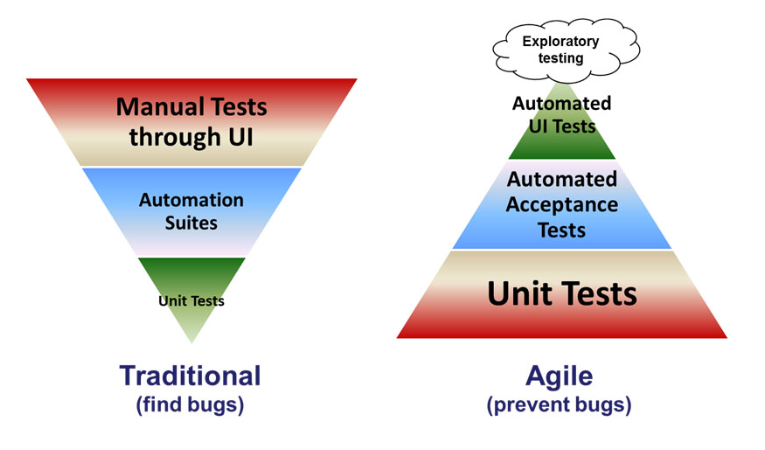
Automated tests are a great thing. The purpose of the diagram on the right is to suggest it's important to have more unit tests than UI tests. Yes, of course because it's hard to automate UI tests.
But really, what's more important than anything is that code which is testable should predominate the code which isn't in the first place.