CEDA
CEDA is a high performance cross-platform embedded in-process multi-master replicated database technology suitable for the management of all sorts of data, such as
- spatial data for mining software
- relational data
- CAD drawings
- word processing documents
- multi-resolution terapixel images
CEDA is not client-server. Instead each application has its own in-process copy of the data cached in memory and its own file(s) on secondary storage to persist the data.
There can be thousands of participating databases connected in arbitary topologies. Multi-master data replication using Operational Transformation is key to the impressive characteristics of CEDA.
- Data coherency - the in-process data which is the target of updates is never stale
- Concurrency - each replica can be updated independently and concurrently, without distributed locks or optimistic concurrency control
- Data redundancy - data is replicated - usually on many physical machines, it's virtually impossible to lose data
- Causal consistency - operations are applied in an order which respects causality
- Partition tolerance - the network can partition in arbitary ways
- Availability - each node is available, regardless of whether other nodes go down or the network partitions
- Low latency - data is accessed in-process, there are no network round trips
- Performance - accessing in-memory data allows for extremely high performance
- Simplicity of application code - applications are written like single user applications accessing in-memory data, yet they're multi-user
- Infallible data access - since access to data is in-process, it is infallible, unlike access over fallible networks
- Branching and merging - configuration management on the entire database
- Real-time interactive collaboration - users can see each other's edits in real time, e.g. as they type characters in a document or move objects on a CAD drawing with the mouse
The name CEDA is derived from "DAta CEntric". This is in reference to the Data-Centric Principle
CEDA is well suited to deployment on the cloud, for example on AWS.
The perfectly smooth panning and zooming of images on the scale of Google Earth on a low performance laptop highlights the exceptional performance characteristics of the database engine.
CEDA can scale from one user to many thousands of users which interactively edit very complex and large amounts of data in applications that feel as responsive as single user applications. The data is replicated and synchronised efficiently, and users are able to view and edit their local copy of the data independently of network latency and network failures. The unique and revolutionary algorithms in CEDA typically merge hours of off-line data entry in a fraction of a second.
One of the prime motivations of CEDA is to support robust distributed data management, despite the fact that networks tend to be unreliable, have high latency, low bandwidth etc (see the eight fallacies of distributed computing).
The CEDA implementation avoids numerous software anti-patterns. This helps achieve simplicity, performance and robustness.
CEDA supports reactive programming - by recording dependencies between calculated outputs and inputs, so that outputs are automatically updated as required.
Database replication tends to make application defined messaging obsolete. For example, rather than publish/subscribe events using a message broker or bus, applications simply add events to their local database, or respond to the addition of events in their local database.
The underlying transactional storage engine has state of the art performance, it can readily achieve data ingestion rates at the sustained write rates of the secondary storage devices - even exceeding a gigabyte per second on a single machine. For example, in one comparison it took only 5 seconds to write a million (key,value) pairs totalling 4GB of data on a laptop with a pair of SSDs in RAID0. On the same machine BerkeleyDB took 2 minutes 20 seconds.
Data is replicated
CEDA allows data to be replicated meaning each site has its own copy of the data stored in its own local database. Operations (updates to the database) are exchanged between sites over the network in order to synchronise the databases.

Each site caches data from its local database in system memory, so that both read and write access to the data often avoids I/O.
The data is partitioned into "topics" called working sets. A site only subscribes to the topics it needs.
Applications only access the local database
Applications that view and edit the data only access the local database. The local access is high bandwidth, low latency and always available. Even though applications are multi-user they feel as responsive as single user applications.
The applications don't directly communicate. Instead the CEDA distributed DBMS does all the work. Applications just access the local database and don't have to worry about the network, latency, replication and synchronisation.

Operational Transformation
A key feature is the use of Operational Transformation (OT) to allow user edits to be performed on a local database without latency, and changes (called operations) are sent and merged asynchronously without the need for distributed transactions.
OT allows operations to be applied in different orders at different sites. In the following picture site A generates an operation O1 and concurrently site B generates an operation O2. These operations are applied immediately on the database where they are generated.

Each operation is sent to the peer where it is transformed in such a way that it can be applied in a new context and yet preserves the original intention of the operation. So the two sites execute the operations in different orders and yet they reach the same final state.
The CEDA implementation provides the following consistency guarantees:
- Each site has sequential consistency
- The system provides Causal consistency [
 ].
Potentially causally related updates must be observed in the same order by all sites.
For different sites, concurrent updates may be observed in different orders.
This is stronger than eventual consistency.
It is also stronger than PRAM consistency []
].
Potentially causally related updates must be observed in the same order by all sites.
For different sites, concurrent updates may be observed in different orders.
This is stronger than eventual consistency.
It is also stronger than PRAM consistency [] - strong eventual consistency : any two sites that have received the same set of updates will be in the same state.
- Monotonic - a database will never suffer rollbacks
OT on Text
The CEDA merge algorithms allow for arbitrary merging of changes to text.
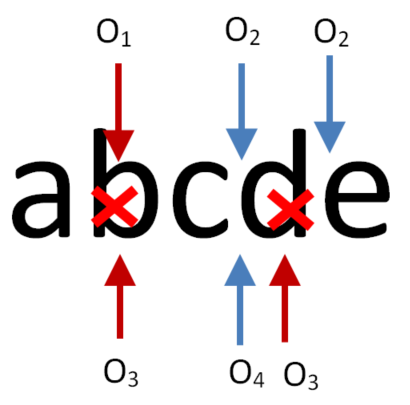
The result is of a merge is always defined, and it is always the union of all the insertions minus the union of all the deletions. The relative order of the inserted characters is always maintained when merging operations.
Operations are streamed between sites
CEDA synchronises databases without distributed transactions.
The operations are streamed asynchronously between sites, as one-way messages, typically over TCP connections, supporting synchronisation rates of millions of operations per second.
Even though there are multiple producers and multiple consumers, every consumer applies every operation from every producer exactly once. Every consumer applies the operations in an order that respects causality. In particular for every producer the operations from a producer are applied in the order they were produced. In other words the operations are applied exactly once in order (EOIO).
For more information see messaging done right
Arbitrary network topologies
CEDA allows for many sites (even hundreds of thousands) in arbitrary network topologies.
The following picture shows an operation generated at one site and propagating efficiently through the network, to be delivered to all sites. At the same time other sites can be generating operations as well, so that at any given time there can be many operations propagating in different directions through the network.

Multi-master
Operations on the same data can be generated at different sites regardless of network partitions. In the database theory literature this is called multi-master replication and is known to be highly desirable but very challenging to implement. Indeed there have been hundreds of papers on the subject in the past 40 years. It is like the Holy Grail for data management systems, especially large distributed systems.
It is also called update-anywhere-anytime replication, because a user is always able to update their local copy of the data, even if they are disconnected from other computers. Indeed the network can be very unreliable, dropping out intermittently all the time, and yet users continue working on their local copy, immune to these problems. The editing experience is unaffected by network latency or disconnections. It means multi-user software is just as responsive as single user software.
Multi-master replication is known to be difficult because of some negative results which have been established in the literature, such as the CAP theorem. CEDA addresses the limitations of the CAP theorem by allowing sites to temporarily diverge as operations are performed in different orders. This is sometimes called eventual consistency.
Once all sites have received all operations they necessarily converge to the same state. CEDA does not compromise on availability and partition tolerance (in contrast to systems which don't are therefore are fragile). When there is a network failure users are able to continue updating their local copies of the data, they are autonomous. The algorithms are very robust, and allow for redundant data paths, failed connections, changes to the network topology and numerous other failure conditions.
In fact CEDA is well suited to replication in extremely unreliable networks. It even allows connections to be broken every few seconds and yet allows robust synchronisation of replicated data. This has been proven to work with reconnections in arbitrary network topologies that change over time. Computers can even connect that have never directly connected before in the past and exchange operations that were received from other peers. The CEDA replication system was first implemented 8 years ago and has been subjected to ongoing, heavy testing with billions of randomly generated operations on randomly generated network topologies with randomly generated reconnections.
Another negative result in the literature is a paper showing that under quite general assumptions replication is not scalable because the computational load increases 1000 fold when the system is 10 times larger. This can easily mean a system cannot keep up with a very modest transaction rate, much to the surprise of its developers. Such a situation is unrecoverable because the load increases as the divergence in the copies of the database increases.
As a result many systems tend to only use master-slave replication. This means updates can only be
applied to one computer (the master
) and updates only propagate in one direction to
all the slaves
.
This is quite limiting compared to update-anywhere-anytime replication. E.g. users cannot work if
they cannot connect to the master and the data entry application may seem sluggish because of network
latency (i.e. the time for messages to be sent to and from the master over the network).
Nevertheless CEDA has a computational load which is proportional to the size of the system, possible because it avoids the assumptions in the literature than imply replication cannot scale. In fact the algorithms are extraordinarily efficient.
Google have tried to support update-anywhere-anytime with Google Wave, a project that caught the interest of industry experts for its exciting proposal to use Operational Transformation to achieve multi-master replication, but their solution doesn't satisfy a mathematical property in the literature called TP2, which means it is not able to merge changes in arbitrary orders for arbitrary network topologies.
CEDA was compared to ObjectStore (a popular object oriented DBMS) in 2004 and CEDA was found to achieve 100 times the transaction throughput in a multi-user database system on a LAN. The benefits of CEDA would have been even greater on a WAN. This is essentially because CEDA uses multi-master replication with fully asynchronous operations, whereas Object Store uses distributed transactions, multi-phase commit and pessimistic locking. ObjectStore is using the conventional approach still emphasised in the database literature today, but which exhibits both poor performance and can't be made robust to network partitions because of the theoretical impossibility of guaranteeing all sites agree to commit a distributed transaction or not when the network is unreliable.
Keys features include:
- Avoids pessimistic locking of data and the complexity and pitfalls with distributed locking, dead-lock detection, and multiphase commit protocols;
- True peer-peer based replication with a symmetric protocol;
- Locally generated operations are always applied immediately without being delayed or blocked - even in the presence of network failure;
- Efficient: The sender only sends operations that have not yet been applied on the receiver. Operations are only sent over a link once; and
- Robust:
- The network can partition at any time in any way and users can continue working;
- There can be arbitrary changes to the network topology at any time. Sites can reconnect in an entirely new topology and exchange operations as required;
- Any site can fail permanently or temporarily. A site can crash and roll back to an earlier state; and
- There can be cycles in the topology
Configuration Management
OT is well suited to both real-time interactive collaboration and configuration management. The latter involves working in isolation and manually controlling when to check-in, check-out, create branches and merge branches.
