Anti-pattern: using OO where the RM is more appropriate
The Relational Model (RM) involves relations which record the extensions of predicates.
Codd's theorem
There is a direct correspondence between expressions of the relational algebra and
(domain independent) expressions of the relational calculus (Codd's theorem).
The relational calculus is essentially the predicate calculus of first-order logic [![]() ].
].
For example:
- DUM corresponds to FALSE
- DEE corresponds to TRUE
- UNION corresponds to OR
- MINUS corresponds to AND-NOT
- (natural) JOIN corresponds to AND
- PROJECT corresponds to EXISTS
The RM has no equal at dealing with collections of facts
There is nothing better than the relational algebra / predicate calculus for expressing queries, integrity constraints, updates and views on collections of facts.
Most OO software developers only know about the RM though their exposure to SQL RDBMS products. Unfortunately both the SQL language and the existing RDBMS products have many significant shortcomings. Perhaps not surprisngly, a lot of OO programmers aren't aware of the tremendous elegance and power of the RM. Ideally they'd read the literature, such as the books by Chris Date and Hugh Darwen.
For example, Eric Evans book Domain Driven Design is full of (trivial) examples which are much more elegantly and simply handled using the RM. E.g. page 19 overbooking policy is just a one liner integrity constraint under the RM.
One of the main reasons for the OO/RM impedance mismatch is because OO is poor at dealing with collections of facts.
Many simple predicates
The most natural way to apply the RM is to use many simple predicates.
Consider these predicates about humans (we avoid a more realistic but esoteric business domain here, because that would be a distraction from the general point being made):
father(F,C) :- F is the father of C
mother(M,C) :- M is the mother of C
married(A,B,D) :- A and B were married on date D
born(P,H,D) :- P was born on date D in hospital H
died(P,D) :- P died on date D
loves(A,B) :- A loves B
hates(A,B) :- A hates B
employs(P,C) :- P employs C
(etc)
Each relation records the extension of a simple, easy to understand predicate about the world.
This tends to avoid the need for nullable attributes, which is a good thing because instantiating a predicate to give a proposition, by substituting NULL for one of its parameters, doesn't give a meaningful proposition.
Note that it's possible for an RDBMS to allow high performance when using large numbers of simple predicates, by using denormalised representations.
Tuple and relation types as first class citizens
A general purpose programming language should support parameterised tuple and
relation types, and the operations of the relational algebra as
first class citizens [![]() ].
].
This would allow code like the following:
auto R1 = relation<int x, int y>{
{(x,1), (y,2)},
{(x,1), (y,5)} };
auto R2 = relation<int y, int z>{
{(y,2), (z,10)},
{(y,2), (z,20)},
{(y,3), (z,4)} };
auto R3 = PROJECT<x,z>((R1 JOIN R2) WHERE x>0);
and the compiler deduces the type of R3.
This approach eliminates the need for an O/R Mapping, and the limitations involved with using OO to manage collections of facts.
OO classes don't provide adequate types for queries
It is naive to think OO classes in the manner used by Evans are suitable for all the relation/tuple types that can arise when dealing with collections of facts. The number of types required grows exponentially with the number of attributes. This can be a vast number.
Consider the following class based on Evan's book on page 99 (showing just its member variables):
class Customer
{
int customerId;
string name;
string street;
string city;
string state;
}
Instances of this class are intended to record tuples of the predicate:
customer(customerId, name, street, city, state)
What OO class is used for the tuples in the extension of the following predicate?
EXISTS street, city customer(customerId, name, street, city, state)
It seems to require another kind of Customer class:
class Customer2
{
int customerId;
string name;
string state;
}
This is just the tip of the iceberg.
Class hierarchies
How would the information contained in hundreds of predicates about humans be mapped to OO classes?
Trying to record all this information using a class hierarchy is extremely cumbersome, particularly as it suggests a need for multiple inheritance and in any case doesn't fit well with the fact that usually in OO languages objects cannot change their type over time. For these reasons it is easier to use a small number of "big" classes with lots of nullable attributes, but that goes against the most natural way to apply the RM.
A human might be classified in the following ways at different times in their career:
- WageEmployee
- SalaryEmployee
- SalesEmployeeOnCommission
- ManagerEmployeeOnSalesCommissionWithShareHolding
Martin Fowler in his book Patterns of Enterprise Application Architecture, page 45 says
There's another kind of hierarchy that causes relational headaches: a class hierarchy linked by inheritance. Since there's no standard way to do inheritance in SQL, we again have a mapping to perform
There's no relational headache. The headache is the pointless OO class hierarchy.
He provides the following diagram to illustrate the approach of using one table to store all the classes in a hierarchy. He calls this the Single Table Inheritance pattern.
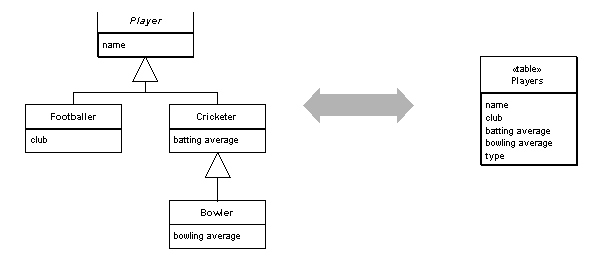
Similarly he discusses the Concrete Table Inheritance pattern, which has a table for each concrete class in the hierarchy, and the Class Table Inheritance pattern, which has a table for each class in the hierarchy.
These are anti-patterns for designing a relational schema. It is better to determine the predicates
according to normal forms [![]() ]
which depends on the functional dependencies [
]
which depends on the functional dependencies [![]() ].
].
One of the nice features of the RM is that you don't have to make arbitrary decisions about how to classify things. From a point of view which is focused on the predicates and logic, the OO class hierarchy is an arbitrary and pointless distraction.
Using state machines to encode data
A relational database can be regarded as a variable called a dbvar
which records a value, called a dbvalue.
A dbvalue is a tuple of relations.
All the information is encoded with pure data types.
By contrast, when OO is used to record collections of facts, it emphasises interacting state machines. This is the state machine instead of datatype anti-pattern.
What does object identity mean?
It seems strange to think of an entity in the real world like an employee as being associated with an object in memory with state, behaviour and identity. In raises strange questions like:
- Is an Employee class a data type?
- Is there a distinction between object identity testing and object equivalence testing on class Employee? (a == b versus a.equals(b) in languages like C# or Java)
- Can two object instances of class Employee represent the same human?
- Can objects of class Employee be copied or cloned?
- What does deleting an Employee object mean? Does it mean the human ceases to exist?
- Is an object instance of an Employee class an employee record, or is it pretending to be a thing with object identity that together with other objects is somehow supposed to model entities in the real world in some kind of one-to-one correspondence?
These are pretty basic questions about the semantics, and yet Eric Evans just dives in with his Domain Driven Design approach, modelling the real world with objects, without explaining the semantics.
OO reaction : define models for a specific business capability
One of the motivations for microservices and decentralised databases is to provide some chance for OO class hiearchies to actually be usable.
For example consider the following blob post by Udi Dahan: Don’t try to model the real world, it doesn’t exist
Paraphrasing a bit this says:
Don’t try to model the real world, it doesn’t exist. The thing is that a single physical entity can have multiple meanings to various stakeholders. The important thing to note is that the data relevant to each of those meanings is so different from one stakeholder to another. I know it feels counter-intuitive to not have a single class representing a single physical thing. It feels like it’s the exact opposite of Domain-Driven Design. It feels anti-object-oriented. But remember, most stakeholders you talk to don’t focus on the physical elements either. The one thing left to be modeled from “reality”. And that’s identity. Forget about reality – all that exists is perceptions.
By contrast with the RM you can model an entity like a customer in arbitarily many ways by defining dozens of predicates which reference a customer by an identifier.
You can keep adding more and more predicates to support new meanings for new stakeholders.
There's only an OO class called Customer that keeps changing and gets more and more complicated if you are naive enough to record the information using OO classes in the first place.
Do domain objects need encapsulation?
Udi Dahan in his blog post Watch out for superficial invariants (2014) discusses an invariant such as: an employee cannot take more annual leave than they have. He says:
This falls into the trap of applying mathematical thinking (which we developers possess in great quantities) to the business world. The business world isn’t that mathematical (in general), and tends to have many more shades of gray expressed as “business rules” which can, and do, change.
He is essentially saying domain objects tend not to have class invariants [![]() ].
That begs the question of why use OO for domain modelling.
The raison d'être to want encapsulation [
].
That begs the question of why use OO for domain modelling.
The raison d'être to want encapsulation [![]() ] is to
allow class invariants to be enforced.
] is to
allow class invariants to be enforced.
Rules – not invariants
Udi Dahan says:
Rules – not invariants
Employees can’t take more annual leave than they have.
… unless their manager approves.
… but that’s only up to 2 days.
… unless their manager is a VP, and then it’s up to 5 days.
… and that negative balance will be deducted from next year’s leave.
… Oh, and if the employee leaves the company before then, then the value of those negative days will be deducted from their final paycheck.
A very easy and direct way to express these rules is using predicate logic, expressed in terms of predicates such as:
| Relation name | Predicate |
|---|---|
startEmployment |
Employee [EmployeeId] started employment at [StartTime] |
endEmployment |
Employee [EmployeeId] ended employment at [EndTime] |
manages |
Manager [ManagerId] manages employee [EmployeeId] from [StartTime] |
salary |
Employee [EmployeeId] is paid salary [Salary] from [StartTime] |
paycheck |
Employee [EmployeeId] was paid [Payment] on [PaymentTime] |
vicePresident |
Employee [EmployeeId] became a vice president at [StartTime] |
leaveRequest |
Employee [EmployeeId] submitted leave request [RequestId] at time [TimeSubmitted] for the period from [StartTime] to [EndTime] |
leaveApproved |
Request [RequestId] was approved by manager [ManagerId] at time [TimeApproved] |
leaveRejected |
Request [RequestId] was rejected by manager [ManagerId] at time [TimeRejected] |
leaveTaken |
Employee [EmployeeId] took annual leave for the period from [StartTime] to [EndTime] |
In a complex system there are lots of predicates. Fortunately each predicate is independently meaningful to a domain expert.
Large numbers of simple predicates represents the ultimate in loose coupling. The only thing tying all these predicates about employees is the existence of an employee identifier. You can't get better decoupling than that.
It is usually possible to partition the predicates into groups according to natural divisions in the business ("vertical slices") such as:
- Staff structure
- Staff payroll
- Annual leave
Nevertheless it should be borne in mind that the underlying predicates themselves already involve the most loosely coupled data model that could possibly be expressed.
There tend to be more predicates in this representation than there are classes in an OO domain model. OO models compensate for inappropriate taxonomies by using fewer classes and more member variables. For example it's problematc to have classes like SalariedEmployee, SalesEmployee, Manager and VicePresident because it leads to multiple inheritance and also objects cannot change their type over time. To avoid the unfortunate complexity and logically unnecessary coupling that arises in OO models, Eric Evans says you need to design multiple domains models using bounded contexts - and these arise from the vertical slices through the business domain.
Notice in these predicates there is an emphasis on recording events that occur in time. This is appropriate for modelling long running business processes.
It allows for expressing things like the amount of leave currently available to an employee - which equals what they have accrued minus what they have taken. What they have accrued depends on how long they have been employed, and what they have taken involves aggregation. This is easily expressed using the relational algebra.
The amount of money owing to an employee equals the amount they have accrued minus the amount they have been paid so far. These in turn involve aggregates accounting for things like changes in their salary over time, taking leave without pay etc.
This only involves defining views which are pure calculations over the data that are easily expressed using the relational algebra and functional programming. What does this have to do with implementing data types or state machines? In other words what does this have to do with OO?
Consider Martin Fowler's post on AnemicDomainModel where he compares using OO to express business rules in domain models versus "procedural style design":
The basic symptom of an Anemic Domain Model is that at first blush it looks like the real thing. There are objects, many named after the nouns in the domain space, and these objects are connected with the rich relationships and structure that true domain models have. The catch comes when you look at the behavior, and you realize that there is hardly any behavior on these objects, making them little more than bags of getters and setters.
...
The fundamental horror of this anti-pattern is that it's so contrary to the basic idea of object-oriented design; which is to combine data and process together. The anemic domain model is really just a procedural style design.
It's common to see discussions about Rich Domain Models (RDM) versus Anemic Domain Models (ADM). For example:
- Stack overflow discussion Anaemic data model ( ADM Vs RDM) 2012
- Blog post The Anaemic Domain Model is no Anti-Pattern, it’s a SOLID design 2014 by SAPM.
- Blog post Rich Domain Is SOLID , Anaemic Domain Is An Anti Pattern by Sapiens Works, 2014
- Code project article Anemic data models (ADM) VS Rich Data Models (RDM) in C# by Shivprasad koirala, 2015.
- Blog post The Rotten Domain Model is dead; long live the Abstracted Domain Model by David Arno, 2016
- StackExchange question DDD - Is anemic domain model an antipattern? Shoud we be using rich domain models? 2017.
A more interesting comparison is between OO and predicate logic / relational algebra / functional programming for the purpose of expressing business rules in domain models. In that case OO loses badly.
OO has its place for things like systems programming, user interfaces, implementing data types and implementing a DBMS, but it's a remarkably poor choice for expressing business rules in domain models.