Approaches for high performance distributed workloads in CEDA
Using clusters of compute nodes to perform pure processing tasks
A Task Executer service allows for executing pure processing tasks on a cluster of machines (compute nodes). By pure we mean that for a given task
- all the inputs are sent in a single input message; the execution of the task doesn’t require any additional state.
- all the outputs are returned in a single output message
The compute nodes are not generic. It is assumed application specific executables are installed on the nodes allowing for deserialising each input message, executing the task and serialising the output.
Both the input and output messages are sent as one-way messages.
The CEDA process managing a database instance creates pure CPU tasks, sends them to be executed and processes the results (e.g. persisting the results in its database). In this manner the database instance is able to scale out its processing load in a dynamic manner, using pure compute nodes.
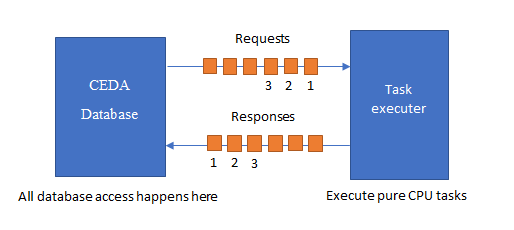
It is typically very easy for a single CEDA database process which off-loads expensive CPU work to saturate the I/O available on the network cards and secondary storage devices on that physical machine. In other words, it is easy to offload the processing such that the CEDA database process becomes I/O bound not CPU bound.
It may be appropriate to deploy the CEDA database on a physical machine with lots of RAM and I/O capability, perhaps using RAID arrays of SSDs and/or multiple network interface cards.
The input messages are sent to a load balancer (below described as a Multithreaded Task Executer or Dispatcher), which forwards on each message to some compute node. The node processes each message it receives and sends the results back to the load balancer, where the results are then routed back to the original sender. This is all transient, no messages are made persistent. Communication uses reliable, ordered, exactly once point to point messaging trivially implemented on TCP.
Task executer
A task executer processes pure CPU tasks. There is an input stream and an output stream which involve ordered delivery transient message queues. The output messages are returned in an order consistent with the input messages, so it is easy for the client to associate responses with requests.
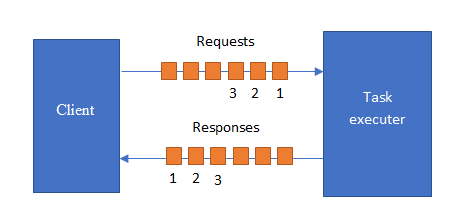
Single-threaded task executer
A single-threaded task executer can sit in a loop reading each request, processing it, then sending back a response.
while(1)
{
inputMessage = inputQueue.Read();
outputMessage = ProcessMessage(inputMessage);
outputQueue.Send(outputMessage);
}
Multi-threaded task executer
A multi-threaded task executer ("dispatcher") can read many requests, execute them in parallel, and return responses as they become available. However, it will need to buffer responses to return them in order.
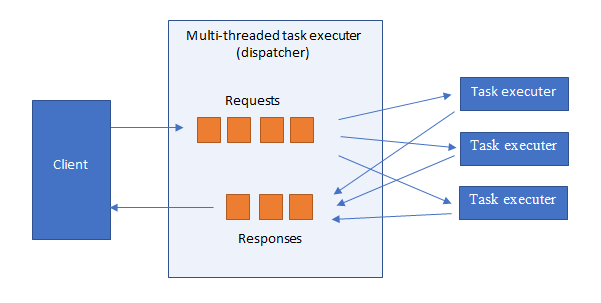
We assume ordered delivery of requests/responses between dispatcher and each task executer.
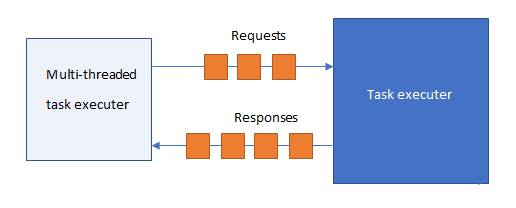
The dispatcher can easily calculate the number of pending tasks given to each of its task executers. On that basis it can load balance by assigning tasks to the executer which has the lowest number of pending tasks.
A dispatcher is generic - i.e. it can be fully implemented independently of the types of input/output messages which may be processed. As far as it's concerned the messages are just blobs.
Auto-scaling
We can also have a concept of task executers that connect to the dispatcher in order to become available to handle work items. Task executers might be added dynamically to handle high demand.
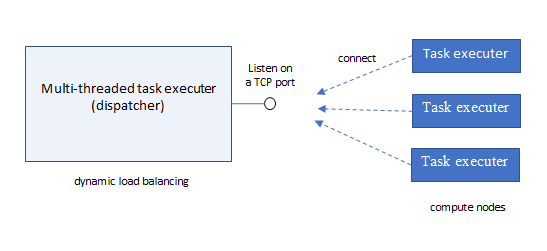
A dispatcher can deal with an unresponsive task executer by dropping the connection and giving its work items to other task executers (to allow this the dispatcher needs to buffer pending request messages so they can be resent).
On cloud providers like AWS where machines and networks are in practise highly reliable (MTBF measured in months or years) one expects this to be a rare event, so doesn’t need to be optimised. Likewise persisting messages or supporting some notion on recovery isn’t helpful, it is better to design the system for high throughput using transient message queues.
Persisting messages or supporting some notion of recovery by the task executer isn’t helpful, it’s an anti-pattern. It makes the system much more complicated, much less robust and much less efficient. Only database management systems should persist data. It raises too many questions about consistency. For example it can mean the client is forced to flush its own state to disk every time it sends a message in order to be consistent with the persistent messages.
It is better to design the system for high throughput using transient message queues and task executers that don’t have overheads associated with recovery.
A dispatcher is itself a task executer, so dispatchers naturally compose. So it's easy to write a dispatcher which is itself scalable.
Throttling the client
An important notion is to consider what happens when the task executer can’t keep up with the client. One mechanism is that the request queue becomes full, preventing the client from sending more messages. Another is that the client avoids sending too many messages that are pending responses. This latter mechanism can be better because there is a tendency these days to have large buffers and high bandwidth networks. In some situations it is better to throttle the producer before buffers are filled, rather than allow latency to go unchecked.
Having the client throttle what is sent on the basis of what is received is easier if the responses are ordered (because the client simply subtracts the receive sequence number from the send sequence number).
Why do we prefer ordered message queues?
In a nutshell, pipeline architectures are easier to understand, simpler to code and more efficient.
Ordered queues are perfectly consistent with parallelism! The multi-threaded task executer can buffer many out-of-order responses while one of its threads is executing a long running task. With sufficient buffering the multi-threaded task executer can keep all its threads 100% utilised.
Ordered messages queues is a better fit to TCP which is already ordered delivery. Ordered messages queues is a better fit to a single-threaded task executer which gives ordered responses.
Ordered delivery is more space efficient on the wire. There’s no need for explicit sequence numbers in the messages. It can allow for better compression (using tokens to represent parts of messages that tend to be repeated).
Ordered delivery is great for driving a state machine using many small messages. E.g. OpenGL graphics commands depend on ordered delivery.
Consider the alternative which is not to impose an order on the responses. This makes the task executer easier to implement but the client harder to implement. From the perspective of overall code complexity it is better to push complexity into the multi-threaded task executer, because we have very few implementations of task executers, and many implementations of clients.
A possible downside of ordered responses is that the client is prevented from handling out-of-order tasks that have already completed, but are pending delivery. Ideally tasks don’t have very long running times, because tasks are relatively small. Separate channels can be used to deal with significant mismatches in running times. These can be multiplexed on a single TCP connection.
Supporting unordered responses
Ordered responses can be used as a building block to construct a system allowing unordered responses! This is achieved by multiplexing N different channels on the one TCP connection, where each channel has ordered responses, but each channel works independently.