The fallacies of distributed computing
One of the prime motivations of CEDA is to support distributed data management, despite the fact that networks tend to be unreliable, have high latency, low bandwidth etc. Programmers new to distributed applications invariably make the following false assumptions
- The network is reliable.
- Latency is zero.
- Bandwidth is infinite.
- The network is secure.
- Topology doesn't change.
- There is one administrator.
- Transport cost is zero.
- The network is homogeneous.
These are known as the fallacies of distributed computing [![]() ].
].
Some impossibility results in distributed computing
There are many impossibility results in distributed computing. For example see A hundred impossibility proofs for distributed computing by Nancy Lynch 1989, and Hundreds of impossibility results for distributed computing by Faith Fich and Eric Ruppert 2003.
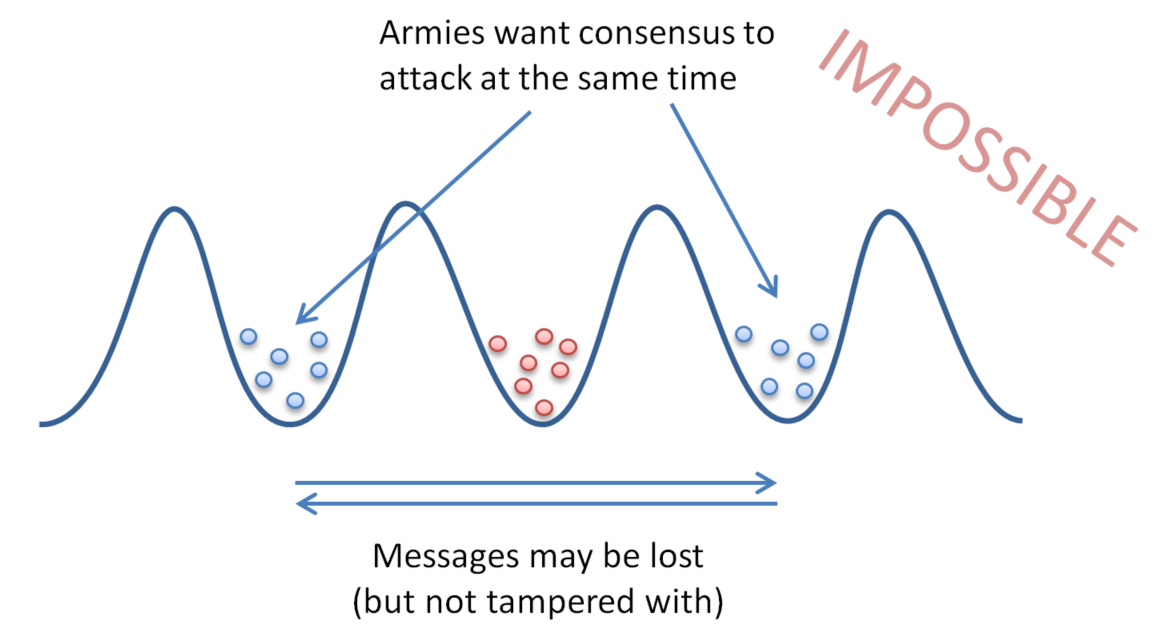
Two generals' problem
It is impossible to coordinate simultaneous action. This doesn't contradict atomic commit protocols like 2PC which allow for coordinating eventual agreement. i.e. under 2PC all nodes eventually agree to commit or abort the transaction (assuming they eventually recover).
FLP Theorem
Fischer, Lynch and Patterson 1985 won the Dijkstra award given to the most influential papers in distributed computing.

The FLP theorem states that in an asynchronous network where messages may be delayed but not lost, there is no consensus algorithm that is guaranteed to terminate in every execution for all starting conditions, if at least one node may fail-stop.
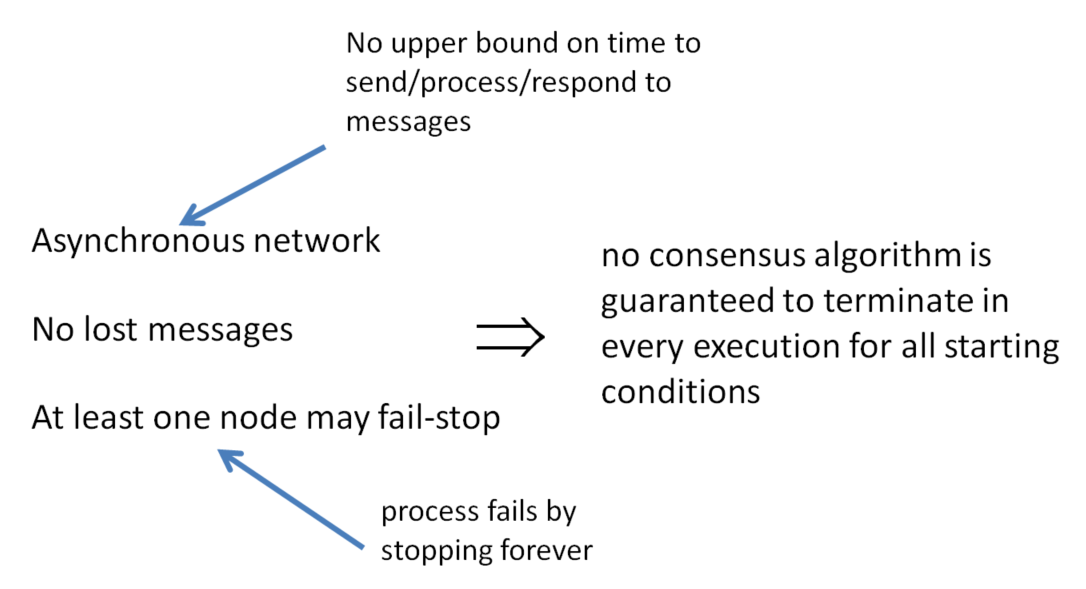
Asynchronous: There is no upper bound on the amount of time processors may take to receive, process and respond to an incoming message. Therefore it is impossible to tell if a processor has failed, or is simply taking a long time to do its processing.
Processors are allowed to fail according to the fail-stop model - this simply means that processors that fail do so by ceasing to work correctly.
Independent recovery
No independent recovery means that nodes are unavailable even though they haven't failed.
Theorem:
There exists no distributed commit protocol with independent process recovery in the presence of multiple failures.
CAP theorem
Another impossibility result, the CAP theorem says you can't have all three of Consistency, Availability and Partition Tolerance. Under OT we give up on strong consistency and only require consistency once all operations have been received at all sites (i.e. we allow temporary divergence and only require eventual consistency).
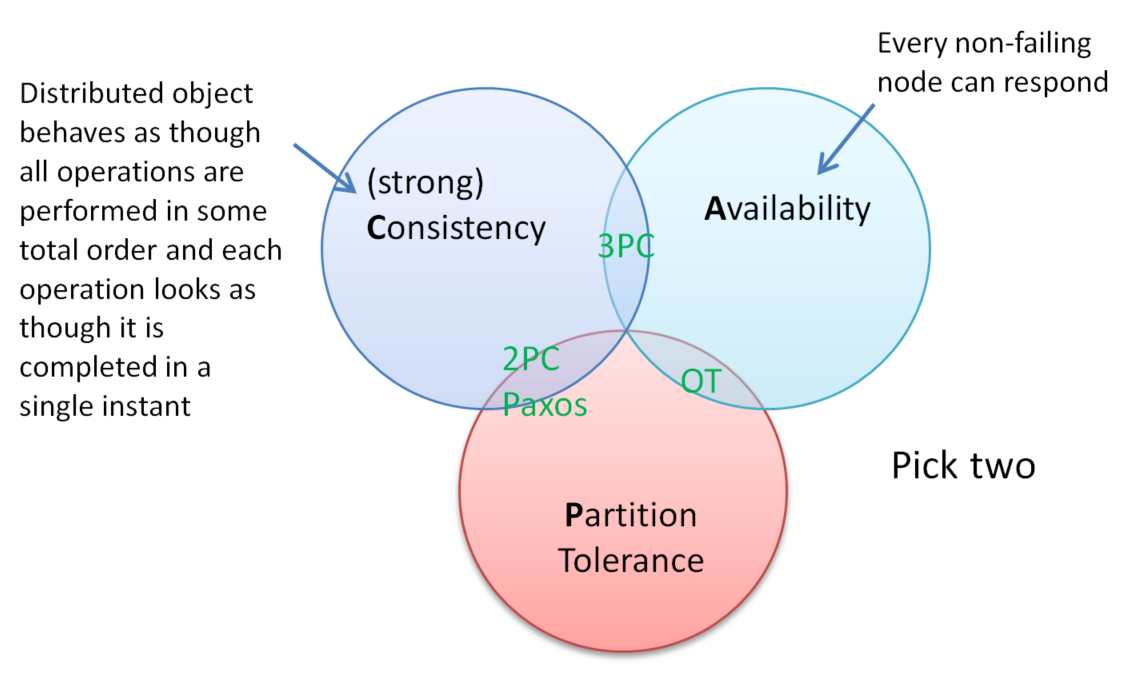
In systems involving cloud computing and internet-scale services where nodes may be on different sides of a continent or across oceans, we certainly need partition tolerant algorithms.
Distributed transactions are evil!
Distributed transactions are slow and error prone. It's easy to find negative comments about them on the Internet
It comes as a shock to many, but distributed transactions are the bane of high performance and high availability
...Yes they're evil. But are they a necessary evil - that's the real question. ...I believe they are indeed the worst sort: necessary. We're all dooooooomed......
... at the end of the day, however, it is impossible. Nature finds a way to make your life miserable, and all because of these horrid distributed transactions.
The dangers of replication
Jim Gray, Pat Hellend, Patrick O'Neil, Dennis Shasha published a paper in 1996 on Update-anywhere-anytime transactional replication, showing under quite general assumptions that there is a scalability problem:
Their conclusions were somewhat pessimistic:
10x increase in nodes and traffic implies a 1000x increase in deadlocks or reconcilliations
CEDA avoids certain assumptions made in this paper and allows for merging which is linear in the number of nodes and traffic.
2 Phase Commit (an atomic commitment protocol)
For distributed transactions (an Atomic Commitment Protocol)
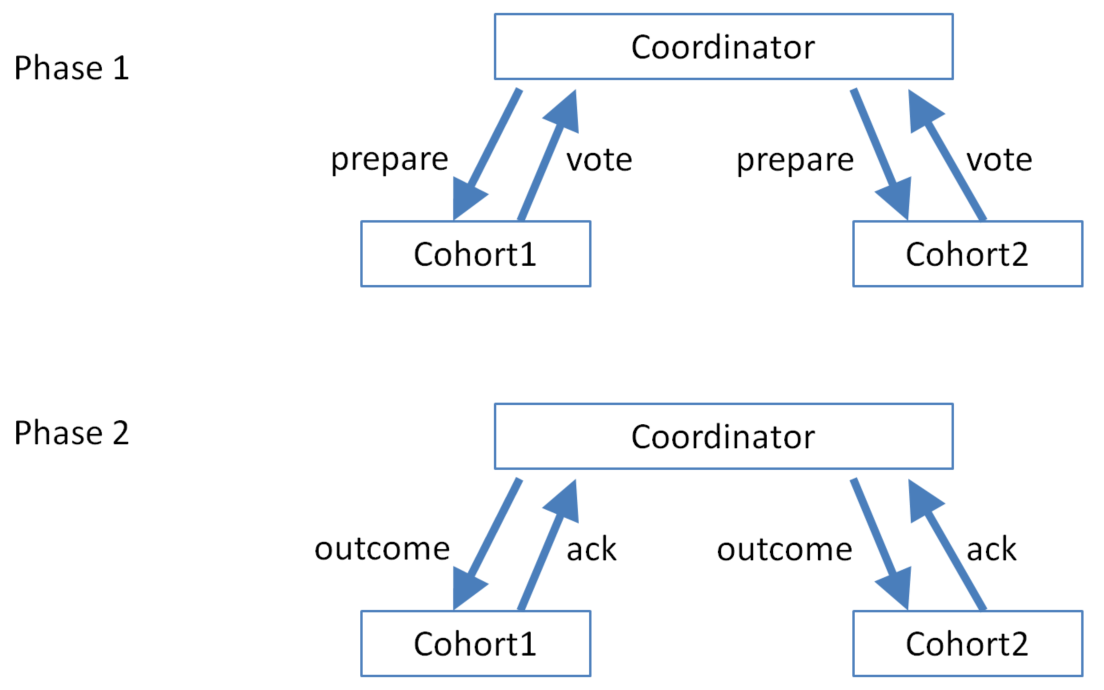
The protocol assumes that there is stable storage at each node with a write-ahead log, that no node crashes forever, that the data in the write-ahead log is never lost or corrupted in a crash, and that any two nodes can communicate with each other.
In phase 1:
- The coordinator sends a PREPARE message to all cohorts
- Each cohort may respond with an ABORT-VOTE, or stably record everything needed to later commit the transaction and respond with a COMMIT-VOTE
The coordinator records the outcome in its log (COMMIT iff all cohorts voted to COMMIT, ABORT otherwise).
In phase 2:
- The coordinator sends an outcome message (COMMIT-VOTE or ABORT-VOTE) to all cohorts
- The cohort writes the transaction outcome to its log (after this, it never needs to ask the coordinator for the outcome again if it crashes), and replies with an ACK message.
The coordinator writes an END message to its log, which tells it not to reconstruct in-memory information about the transaction on recovering after a crash.
Location transparency
There are fundamental differences between in-process and inter-process communication that ruin the whole premise of location transparency.
